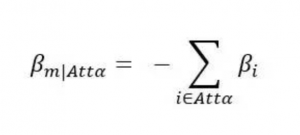早期,我们曾使用简单的回归来分析联合分析的数据。但是随着产品的复杂程度的增加,这种方式就不太适用了。一方面是当产品的属性和水平较多时,每个消费者需要评估的概念产品数量变得更多,即便通过试验设计的方式,每个消费者也可能需要评估几十甚至上百个概念产品,而消费者不可能有耐心完成这么冗长的评估;另一方面在于打分这种评估方式存在很多缺陷,不同的消费者理解打分尺度是不同的。因此,一种新的联合分析方法走上了历史的舞台,即基于选择的联合分析(Choice Based Conjoint,简称CBC;也有很多学者称为Discrete Choice Model,简称DCM)。
CBC需要消费者回答的问题更加贴近消费者真实的消费决策,即消费者是在一些产品中做选择,而非对每个产品打分。但是,对比早期的传统方式的联合分析(对每个概念产品进行评估),CBC(从若干个概念产品中选择最偏好的产品)的数据收集效率较低。消费者在做出选择之前必须比较多个概念产品的信息,而消费者的选择只是表明他们最喜欢那个产品而非其对每个产品的偏好强度。
因此,研究者往往需要把很多消费者的CBC选择数据堆加在一起,形成一个很大的数据集来进行效用值的估算。因此,逻辑模型(Logit model)成为了CBC早期分析的主流方法。
我们以一个简单的例子来看看CBC数据的逻辑模型是如何编码和估算效用值的。属性水平的效用值是任何联合分析的最基本输出结果,也是最重要的结果之一,所有其他的分析(偏好模拟,属性水平溢价,需求曲线及弹性等)都要基于效用值估算结果。
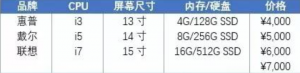
以购买笔记本电脑产品为例,假设我们在购买时需要考虑以下几个属性,每个属性中有不同的水平:
我们每次展示给消费者3个概念产品,让消费者选择最可能购买的产品(或者“都不购买”),并且重复这个过程6次(每次展示的概念产品是不同的)。以下是其中一次展示的概念产品及消费者的选择:
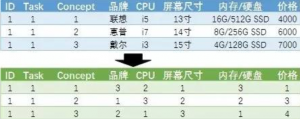
CBC的数据在具体分析前必须进行适当的编码。上面这个选择题的概念产品部分可以转化为以下这种形式的数据:
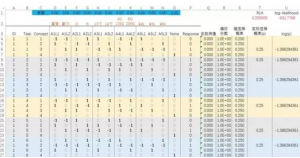
这里的ID代表了受访者的编号;Task则是任务号,每个选择题即是一个任务。每个受访者会做6个这样的选择题(6个任务)。Concept这一列代表了概念产品编号,每个任务中有3个概念产品。每个概念产品的具体展示水平则由后面的数字代表。以第一行数据为例,该受访者在第一题中的看到的第一个概念产品的品牌是3号水平(联想),CPU是2号水平(i5),屏幕尺寸是1号水平(13”),内存及硬盘是3号水平(16G/512G SSD),价格是1号水平(4000元)。
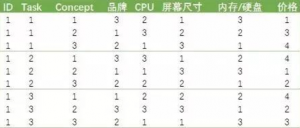
如果我们把这个受访者看到的前3个任务的概念产品设计都按此编码,则数据形式如下:
这样的数据还必须进行进一步的编码。一般可以采用dummy-coding或effect-coding的方式。如果一个属性有k个水平,那么在经过dummy-coding或effect-coding后,我们都会将该属性编码为k-1个变量,因为需要把其中一个水平设为参照水平。
以品牌属性为例,如果把第三个水平(联想)设为参照水平(reference),则dummy-coding和effect-coding后每个属性水平对应的新变量(A1L1,A1L2)值为:
可以看到这两种coding方式的差别仅体现在参照水平的编码上。dummy-coding是将参照水平在新变量上都设为0,而effect-coding则是都设为-1。因此,上面第一个任务经过effect-coding后的数据就是这个样子
除此之外,由于我们在实验设计中加入了“这些都不会购买”(None)选项,每个Task中需要插入第4个Concept,其编码是所有变量都为0,而在最后的None变量中编码为1。如下图所示:
如果我们在这个数据里再加上受访者的选择(Response列),则构成了这个任务的完整数据,这里看到受访者选择了第三个概念产品(Response的第三行为1):
现在我们把所有任务的数据都按照这种方式编码,则最终我们的数据形式为:
(注:这里只展示了第一个受访者coding后的数据)可以看到自变量有12个(对应11个属性水平及1个None水平),因变量有1个。
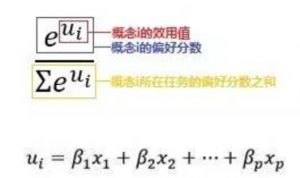
在完成编码后,我们把所有100个受访者的数据叠加在一起。接下来,我们可以使用Excel估算属性水平的效用值。根据随机效用理论(Random utility theory),一般认为人们对不同概念产品的实际偏好效用存在一定的随机性,且这种随机扰动往往服从Gumbel distribution。由此我们可以推算出在面对多个对象时,人们选择第i个概念产品为“最喜欢”的期望概率(也被称为似然度–Likelihood)为:
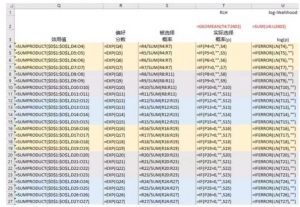
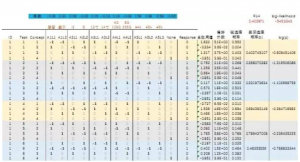
首先我们为每个水平设置一个效应值系数(也称为part-worth或utility,β),如下图中蓝色区域。初始系数不妨均设为0。
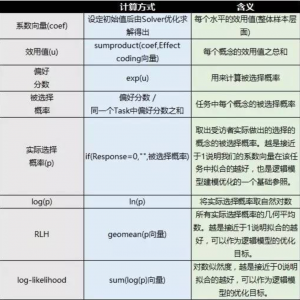
Q列:每一个概念产品的总效用值的计算可以使用sumproduct函数,将系数和对应的effect- coding编码进行相乘。
R列:偏好分数是由每个效用值取自然指数获得的,也就等于“exp(总效用值)”。
S列:被选择概率则是每个concept在该Task中偏好分数的占比,具体计算是用偏好分数除以其所在Task的偏好分数之和。
T列:实际选择概率则是单独将受访者选中的concept的被选择概率取出来,用来计算上面的RLH(Root likelihood,所有实际选择概率的几何平均数)。
U列:log(p)是将实际选择概率取自然对数,用来计算log-likelihood(所有log(p)之和)。
读者也可以效仿下图中Excel的具体公式自己动手试一下:
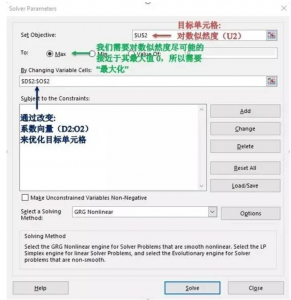
建立好模型后,我们需要用到Excel的优化求解工具(Solver),点击“数据(Data)—>优化求解(Solver)”,并做如下图设置:
我们设置的目标单元格是对数似然度,求解的目标是将其最大化,通过改变系数来达到目标(我们当然也可以通过最大化RLH来求解)。通过求解(点击Solve按钮),我们得到了如下结果:
我们可以用RLH来评估刚才求解出的这组效用值对模型的拟合效果,0.403的RLH表示我们估算出来的属性水平效用值能以40.3%的概率准确拟合这100个受访者的实际选择情况。接下来,我们可以利用这些属性水平的效用值进行市场模拟等分析,我们将会在后续文章中详细介绍。
用Excel Solver的优势是能将整个logit model的编码及分析过程简单直接地展示出来,并且了解条件逻辑模型的优化目标。然而在实际分析中,在数据量较大时Excel处理起来就比较耗时了,而且有出现陷入局部最优解,或者exp函数的数值溢出等问题。如果没有专业商用联合分析软件(如Sawtooth Software,SAS等)的情况下,我们还可以选择开源免费的R来帮我们完成分析。
R语言处理数据不单单能够大大提高效率和估算精度,其开源、轻便的特性也越来越收到数据分析人员的青睐。在条件逻辑模型的估算中,我们推荐使用mlogit拓展包。
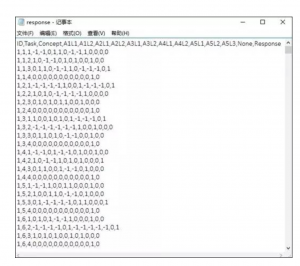
我们把上文已经做好了effect-coding的原始数据保存到一个名为response.csv的文件中。
>install.packages(‘mlogit’)>library(mlogit)
然后将response.csv文件读入(需要事先将该文件所在文件夹路径用setwd函数设置好)
>raw<-read.csv(‘response.csv’)
将concept的数量(4)赋值到变量nAltsPerSet(4=3个概念产品+1个“都不选择”选项)
>tmps<-paste0(“Response~0+”,paste(colnames(raw)[4:(ncol(raw)-1)],collapse = “+”))
>m<-mlogit(as.formula(tmps),data = raw, alt.levels=paste(1:nAltsPerSet),shape=’long’)>m$coefficients
代码中参数的具体作用请查阅mlogit拓展包的说明。在我们这个案例的演示中,5行代码便完成了条件逻辑模型的估算。
可以看到R和Excel Solver得到的结果完全一致,这个结果也和Sawtooth Software或SAS的运算结果完全一致。需要注意的是,由于我们在编码时移除了每个属性中最后一个水平,在Excel和R的结果基础上,我们需要手动将被移除的参照水平的效用值补回(Sawtooth Software会自动完成这个步骤)。基于effect-coding的特性,缺失的参照水平的效用值(记为β m|Attα)等于该水平所在属性(记为Attα)中其他水平效用值之和的负数。
例如“联想”的效用值等于“惠普”和“戴尔”效用值之和的负数,也就是-(-0.322+0.296)≈0.03。将每个被移除的水平补足后,我们会得到如下的最终效用值结果:
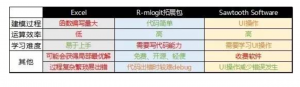
虽然使用不同的软件我们得到了相同的结果,但这三种方法在建模过程、运算效率、学习难度等不同方面都有着不同的表现:
在CBC方法出现的早期,样本层面的逻辑模型(Logit model)的确是最主流的分析模型。但是很快研究人员和营销人员就发现,把所有受访者的数据叠加在一起有可能会低估不同细分人群的偏好差异,如果样本里存在多个不同消费习惯的细分人群,那么样本层面的Logit模型用一组效用值来代表样本中所有个体的偏好肯定是有失偏颇。这个期间,有很多研究者开始使用Latent Class方法来同时实现受访者的人群细分及估算每个细分人群的效用值,并取得了较好的分析结果。
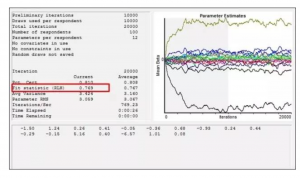
但是技术的发展是无止境的,随着计算机软硬件能力的进一步提升,基于Logit模型的分层贝叶斯算法(Hierarchical Bayesian)被逐步应用到了CBC分析的领域。通过分层贝叶斯算法,我们可以计算每个消费者的效用值。以我们的案例为例,样本层面的逻辑模型估算了1组共16个水平的效用值,而HB算法则会估算100组16个水平的效用值,即每个人都有其各自的效用值。HB算法通过迭代完成估计的,下图是把我们的数据使用HB算法进行迭代的过程:
可以看到HB估算的RLH能够达到0.769,跟样本层面逻辑模型比(RLH=0.403)有显著提升,这一方面反映出我们的100位受访者都较有“个性”,另一方面也体现了HB估算的结果在联合分析中能够大幅提高预测准确率。下图是HB估算出的前20位受访者各自的效用值及拟合优度(RLH)。可以看到HB在每个个体受访者上都大大提升了拟合准确率(样本总体层面logit model得到的RLH仅为0.403)。而且不同消费者的偏好差异也清晰地体现了出来。
因此,目前的CBC类型的联合分析的主流算法已经是HB的天下。不过,逻辑模型依然是各种类型算法的核心,希望大家通过我们的介绍能理解CBC联合分析的原理,解开心中的一些疑问。
本文转载自公众号[消费者研究]版权为上海大正市场研究公司所有,未经许可不得用于任何商业用途。